
Input-Tuning: Adapting Unfamiliar Inputs to Frozen Pretrained Models
Introduction
-
What is the name of the input tuning paper?
Input-Tuning: Adapting Unfamiliar Inputs to Frozen Pretrained Models
Shengnan An
- The input tuning paper addresses a gap that prompt tuning has
mostly been applied to NLU rather than NLG- prompt tuning soft prompts with a frozen model offers high degree of flexibility
- Main examples are T5, DART and my own soft prompt paper
- A problem of the basic prompt tuning method is
failure to adapt a NLG model to unfamiliar inputs- if inputs are unfamiliar full finetuning may be necessary
- example: logic to text translation
- Input Tuning provides a good solution
- if inputs are unfamiliar full finetuning may be necessary
- What are the main contributions of the input tuning paper?
- method outperforms prompt tuning
- can outperform finetuning on various NLG tasks
- Applicable to different models and to both
encoder-decoderand fullyautoregressivemodels
Method
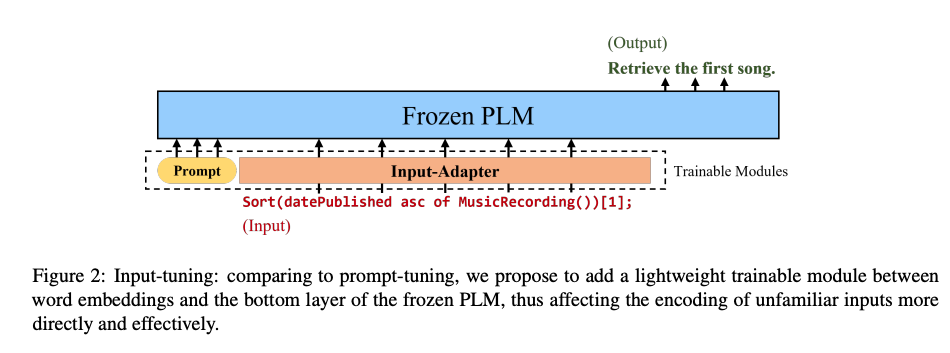
- Input Tuning adds a
trainable layer between embeddings and language model- slightly more heavyweight than standard soft prompt approach
- includes soft prompt as well
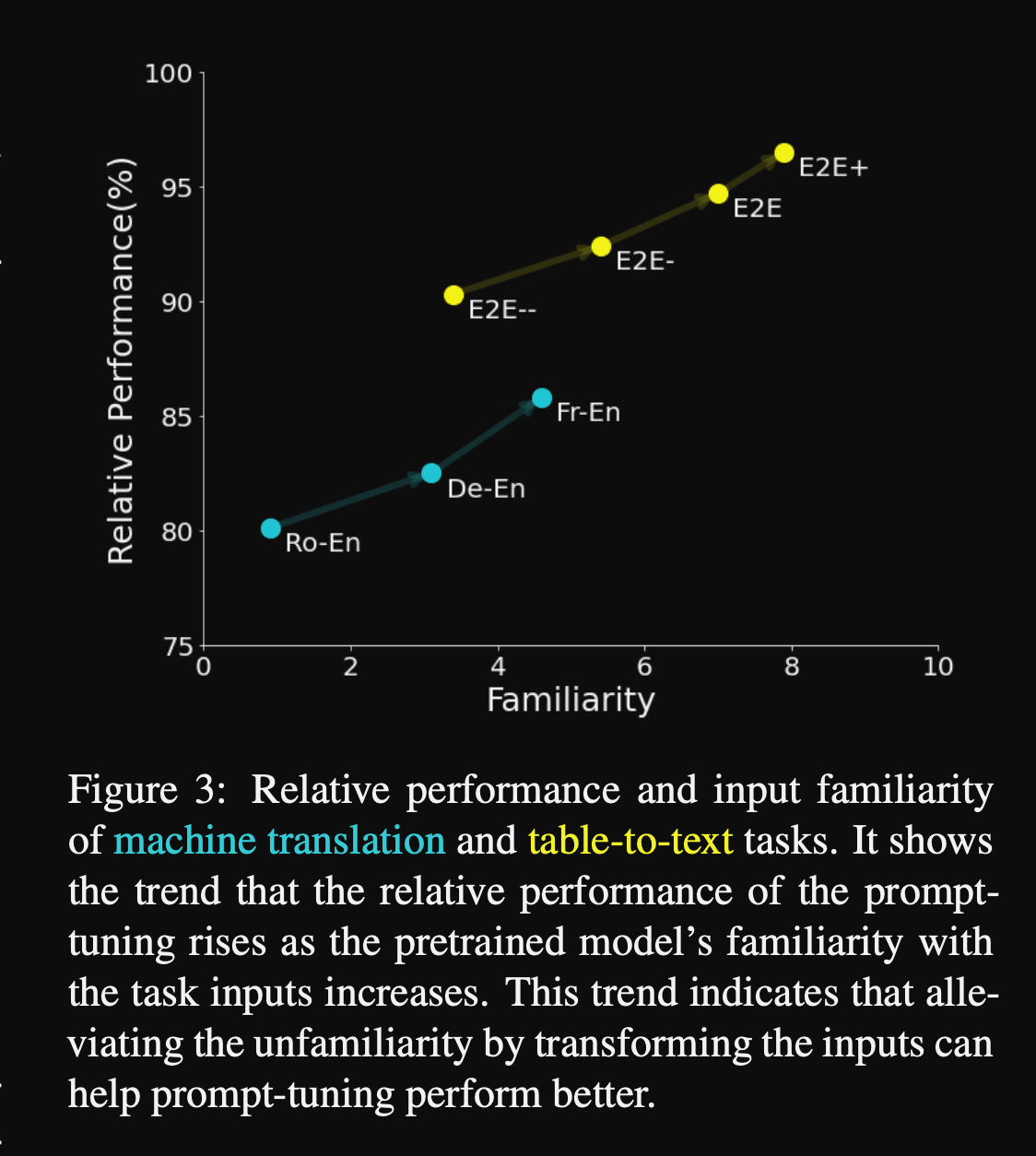
- NLG tasks such as translation may be more difficult for prompt tuning because of the
unfamiliar inputs- encoded tokens from different languages have not been seen before by language model
- prompt tuning (with other parameters frozen) only reaches ~80% of performance of finetuning
- Input tuning attempts to solve this with a tunable layer after the input embeddings
- Input tuning quantifies the familiarity of language model inputs using the
average corpus bigram frequency- for MT more unfamiliar languages will have bigrams appear less often in the corpus
- Input tuning: Machine Translation performance scales with
familiarityof inputs- seems like french bigrams are more common in pretraining corpus
- Also holds for a control E2E task
- The Input Tuning method combines concatenation of a soft prompt with an
additional input adapter- soft prompt randomly initialized from pretrained embeddings (real vocab)
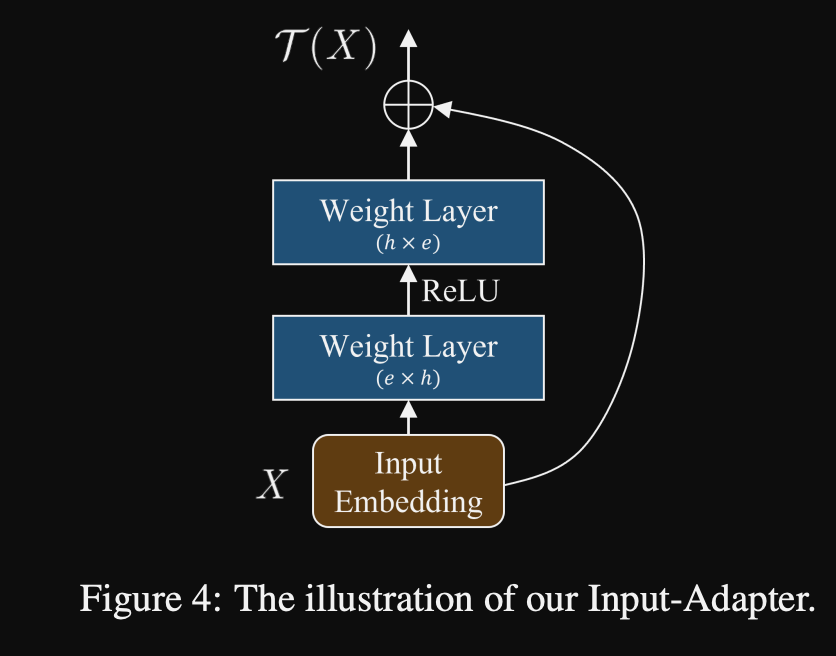
- inner dimension is 2x hidden size (contrary to standard transformer’s 4x)
Results
- The main input tuning experiments are performed with
T5 large- 770m parameters
- Input tuning evaluates on NLG tasks such as
table to textlogic to text and machine translation- all are likely to have unfamiliar inputs
- E2E, DART, ONR
-
Input tuning results: consistently outperforms
soft prompts onlyand approaches full finetuning performance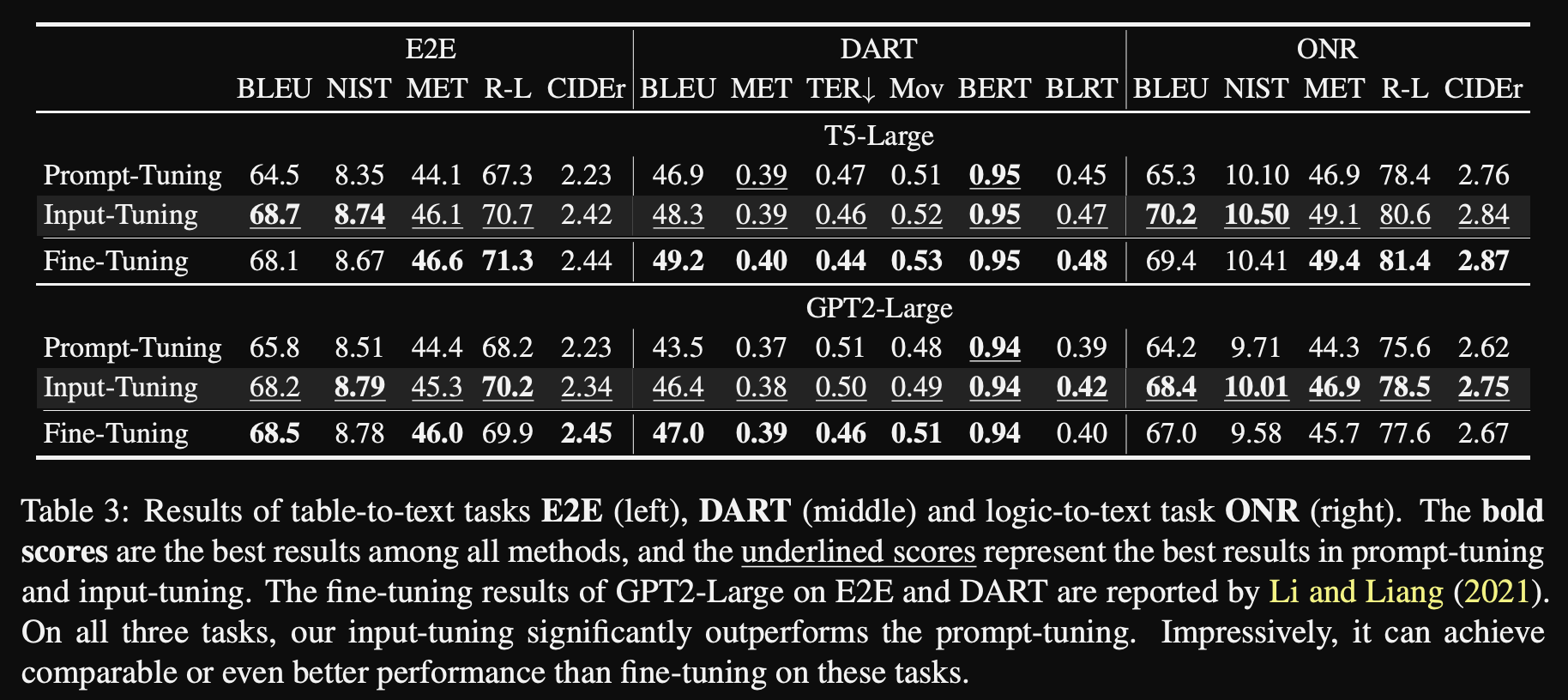
Conclusions
This paper validates a very simple method with great potential to improve parameter efficient adaptation of NLG models.
Notably, their results are achieved using only T5 large which partially contradicts part of the message of The power of Scale For Parameter Efficient Prompt Tuning. It’s very promising to see good results for soft prompt variants with smaller models. Using a separate prompt and input layer for different tasks allows for a 770m T5-large model to be used for many different tasks which can allow scaling to many more applications. For example, one frozen model could be saved on an edge device with different input adapters swapped out to allow translation into multiple languages. By abstracting the embedding layer, computations for translations between different language pairs could even be batched together.
A simple experiment that the author’s could have performed to validate the motivation for tuning would be to measure the average activation magnitude for input tokens in the adapter layer and correlate it with the degree of token familiarity. Given that the input adapter includes a skip connection I would hypothesize that the input adapter would activate more on more unfamiliar inputs that it is trying to adapt to.
Reference
@article{an2022input,
title={Input-Tuning: Adapting Unfamiliar Inputs to Frozen Pretrained Models},
author={An, Shengnan and Li, Yifei and Lin, Zeqi and Liu, Qian and Chen, Bei and Fu, Qiang and Chen, Weizhu and Zheng, Nanning and Lou, Jian-Guang},
journal={arXiv preprint arXiv:2203.03131},
year={2022}
}