
Pretraining without Wordpieces: Learning Over a Vocabulary of Millions of Words
Introduction
This paper introduces wordBERT a model trained with larger tokenizer vocabulary size than standard BERT style models. They show consistent improved performance on NLP tasks particularly in understanding of rare words. Simply expanding the vocabulary of a model at a large scale can help overcome two of the problems described below.
-
The type of wordpiece tokenizations used in standard models have 2 major disadvantages
1) How to get the representation of a word with multiple wordpieces
eg: if lossless is encoded as two tokens, how do we get a single dense representation
2) For cloze completion tasks, how do we know if the mask should be filled by a word with multiple wordpieces.
Method
- WordBERT simply trains an embedding for the top 500k or 1 million words in a corpus
- tokenize using spacy
- WordBERT initializes BERT embeddings from GLOVE embeddings by training a
linear mapping between GLOVE and BERT static embeddings of synonyms- map 300 dimensional GLOVE vector to 768 dimensional BERT vector
- WordBERT overcomes the compuational cost of the softmax using a
sampling based strategy- sample word embedding parameters to update in each batch
Results
-
The wordBERT approach gives
slight improvementon NLP tasks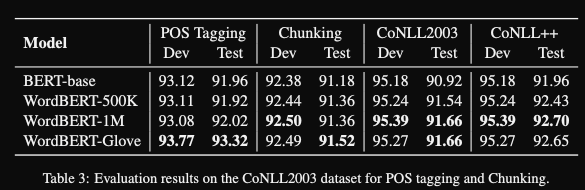
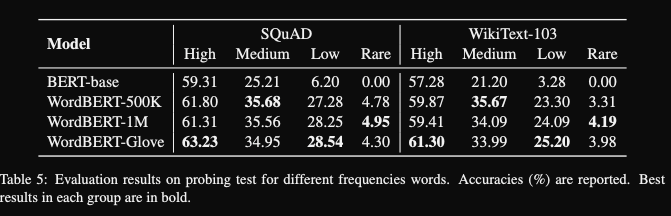
- wordBERT gives decent performance for
MLM masking out rare words- BERT gets 0 because words are not in it’s smaller vocabulary
- wordBERT still does poorly, perhaps because it has some frequency bias
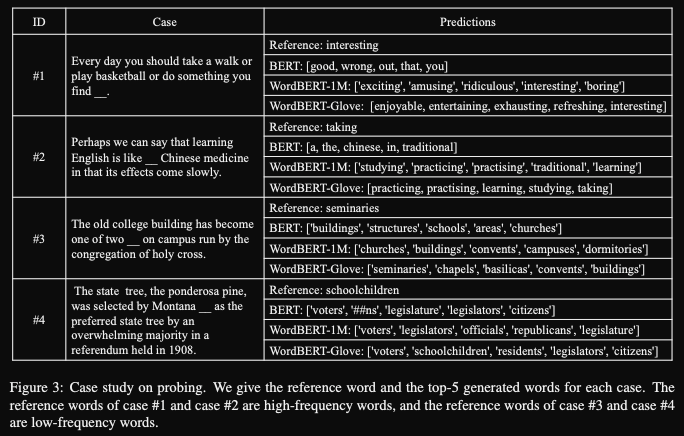
- Qualitatively wordBERT cloze completions might use more
expressive vocabulary- BERT seems biased to short simplistic words
- wordBERT can be faster at inference because
length of the sequence without subwords is diminished
Conclusions
Overall, this was a good basic science paper exploring a very simple approach. They don’t discuss the obvious tradeoff of having to store a much larger vocabulary size. For a BERT-base sized model the embedding parameter cost for wordBERT scales to be much larger than the actual transformer parameters. However, learning without subwords has an appealing benefit of shorter sequence lengths at inference time which they do discuss. I would have liked to see comparisons to roBERTa as well as evaluations on GLUE tasks. One benefit of wordBERT could be the opportunity to train more expressive verbalizers in PET-style architectures. It will be interesting to see how vocabulary size can be evaluated as an additional scaling dimension for large language models.
Reference
@article{feng2022pretraining,
title={Pretraining without Wordpieces: Learning Over a Vocabulary of Millions
of Words },
author={Zhangyin Feng and Duyu Tang and Cong Zhou and Junwei Liao and Shuangzhi Wu and Xiaocheng Feng and Bing Qin and Yunbo Cao and Shuming Shi },
year={2022},
journal={arXiv preprint arXiv: Arxiv-2202.12142}
}