
TABi: Type-Aware Bi-Encoders for Open-Domain Entity Retrieval
Introduction
-
What is the name of the TABi paper?
TABi: Type-Aware Bi-Encoders for Open-Domain Entity Retrieval
-
What is the main contribution of the TABi paper?
TL;DR: State-of-the-art retrievers for open-domain natural language processing (NLP) tasks can exhibit popularity biases and fail to retrieve rare entities. We introduce a method to improve retrieval of rare entities by incorporating knowledge graph types through contrastive learning
- A major long-standing challenge for entity retrieval is retrieving the
long tail- rare entities are unlikely to be retrieved
- still a problem with modern contrastive learning approaches
- Long tail of information retrieval: example
disambiguation- long tail of other Julius Caesars

-
Long tail entity retrieval can be improved by using
entity type information from a knowledge graph - Contrastive Methods: popularity bias: Query embeddings can be closest to the most
popular entity embeddingsfor the mention in the query, regardless of the context
Method
-
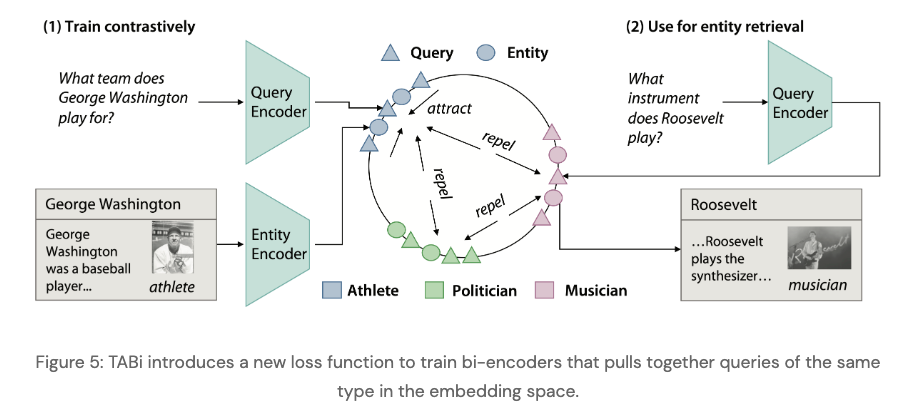
TABi
(Type-Aware Bi-encoders)adds knowledge graph types astextual input to entity encoder - TABi contrastive loss pulls
queries of the same entity type together- type aware loss term
-
TABi type aware loss term positive pairs are
entities of the same type in a batch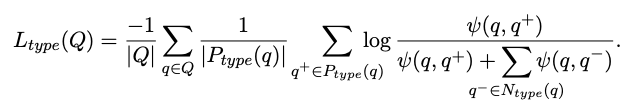
- TABi adds special tokens around
entity mention boundaries
Results
-
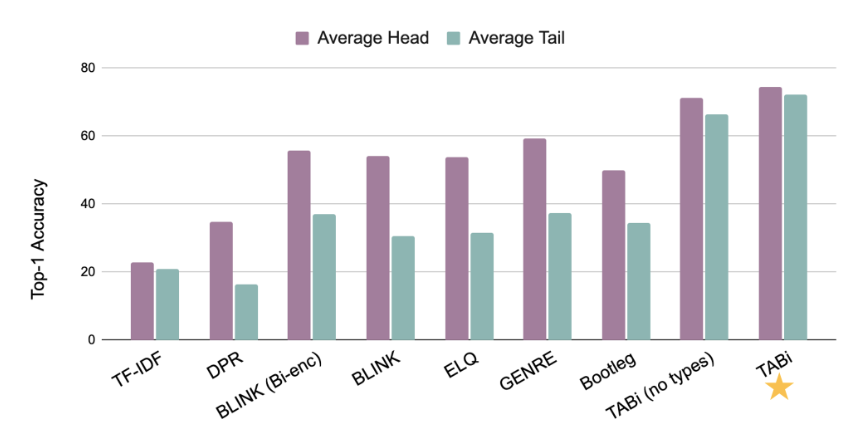
TABi results in better
entity clustering
-
TABI: good results on AMBER and
KILTdatasets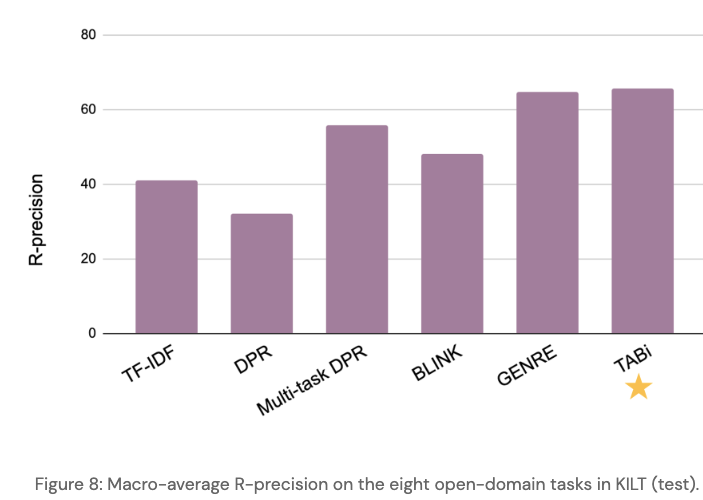
-
TABi robustness: can perform well with
large percentage of incorrect types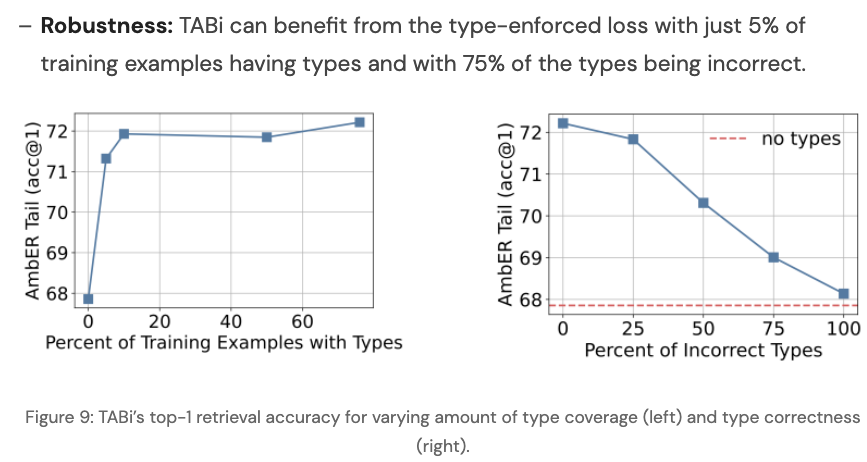
-
New direction in type aware contrastive learning:
- inject data from other structured sources besides knowledge graphs
- incorporate expert knowledge to determine types
Reference
@misc{https://doi.org/10.48550/arxiv.2204.08173,
doi = {10.48550/ARXIV.2204.08173},
url = {https://arxiv.org/abs/2204.08173},
author = {Leszczynski, Megan and Fu, Daniel Y. and Chen, Mayee F. and Ré, Christopher},
keywords = {Computation and Language (cs.CL), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {TABi: Type-Aware Bi-Encoders for Open-Domain Entity Retrieval},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}