
Token Dropping for Efficient BERT Pretraining
Introduction
-
What is the name of the BERT token dropping paper?
Token Dropping for Efficient BERT Pretraining
Le Hou, Richard Yuanzhe Pang
-
What are the main contribution of the BERT token dropping paper?
1) Pretrain BERT models with only a subset of the layers and while focusing on important tokens
2) Identify important tokens during the pretraining process with minimal computation overhead
3) Save 25% of pretraining time
Method
-
BERT token dropping unimportant tokens are
skipped by the middle layers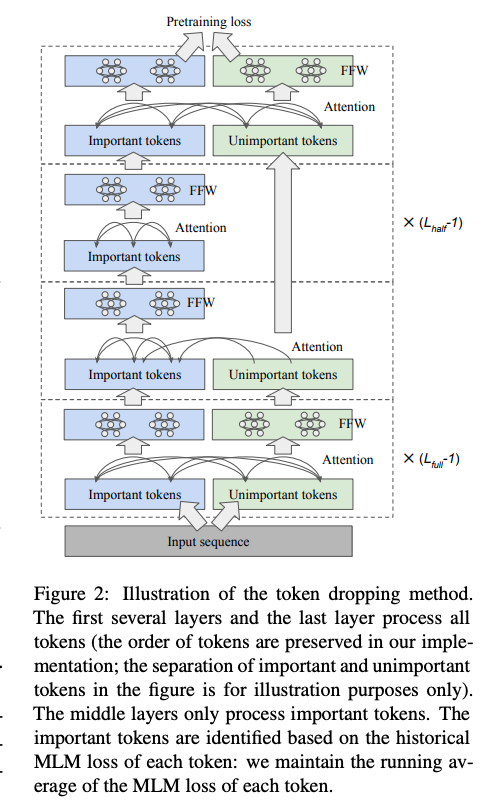
-
BERT token dropping experiments with dynamic cumulative loss based dropping and static
frequency based dropping - BERT token dropping dynamic cumulative loss based dropping drops tokens with the
smallest cululative pretraining loss- loss is accumulated as EMA
- loss being small means token is “easy” to learn
- BERT token dropping static approach drops
most common tokens by frequency
Results
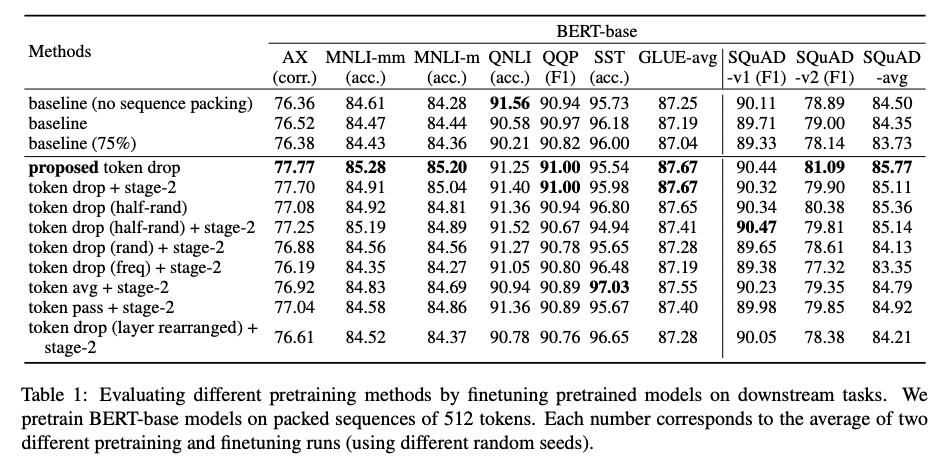
- BERT token dropping results: maintain
accuracy on downstream tasks- reduce pretraining time by 25%
Conclusions
This paper presents a method to reduce BERT pretraining time by dropping uninformative tokens. Broadly I’d describe such methods as having two major components: 1) How to drop tokens and 2) How to decide what tokens to drop. In this paper the method for 1) is to skip dropped tokens in the middle layers of the transformer and for 2) is done using cumulative loss. Meanwhile, FCA BERT means pools the uninformative tokens and uses a weighted attention score to determine which token to drop. Both those papers are applied to reducing BERT inference times. However, this paper aims to speed up pretraining which offers significant computational savings. It would be nice to extend some of the interpretability research into what linguistic properties BERT-like models learn at each layer in order to further motivate a token dropping approach.
Reference
@misc{https://doi.org/10.48550/arxiv.2203.13240,
doi = {10.48550/ARXIV.2203.13240},
url = {https://arxiv.org/abs/2203.13240},
author = {Hou, Le and Pang, Richard Yuanzhe and Zhou, Tianyi and Wu, Yuexin and Song, Xinying and Song, Xiaodan and Zhou, Denny},
keywords = {Computation and Language (cs.CL), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Token Dropping for Efficient BERT Pretraining},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}