
Training an AI to play Incan Gold
Introduction
I implemented a playable version of the board game Incan gold as my final project for my introductory computer science class CS50. I focused on creating AI opponents that were trained by playing against themselves for thousands of games. Incan Gold is a simple yet incredibly fun push-your-luck style strategy game in which players compete to extract loot from an Incan temple. Each turn, a player must choose to either continue onwards into the temple incurring more danger and the possibility of greater reward, or choose to play it safe and go home with their current winnings.
The gameplay is very simple: each turn players make their decision and a card is flipped. The cards can be treasure cards with a point value that is evenly distributed among the active players, or a danger card indicating that the expedition might no longer be safe. Whenever a loot card has a value that cannot be evenly distributed, the remainder is left on the path and can be claimed by any player choosing to leave in a later round. If a second danger card of the same type is drawn, then players who are still active must forfeit their winnings. The game consists of five rounds after which a winner is declared. Strategies can become fairly complex as players must consider the potential danger of going forward as well as the potential reward of sharing loot with fewer competitors.
Methodology
I chose Incan Gold for this project because it involves binary decisions that were easier to model. For each round and turn, each AI player simply chooses either to go forward or to go back. This was my first computer science project before I knew anything about reinforcement learning so I took a naive approach to training the AI players. Each AI player was trained off of the winning moves made by AI players over the course of thousands of simulated games. Subsequent generations of AI players were trained against each other in order to improve performance.
The binary decisions were treated as a machine learning problem with the correct decision predicted based on the game situation. I trained random forest models to predict the move made by the winning player based off of data for thousands of simulated games. The AIs were able to base their decisions off of a number of variables including their current score, the score that they needed to win, the current round of the game, the probability of death on the next card and the current value of their loot.

Results
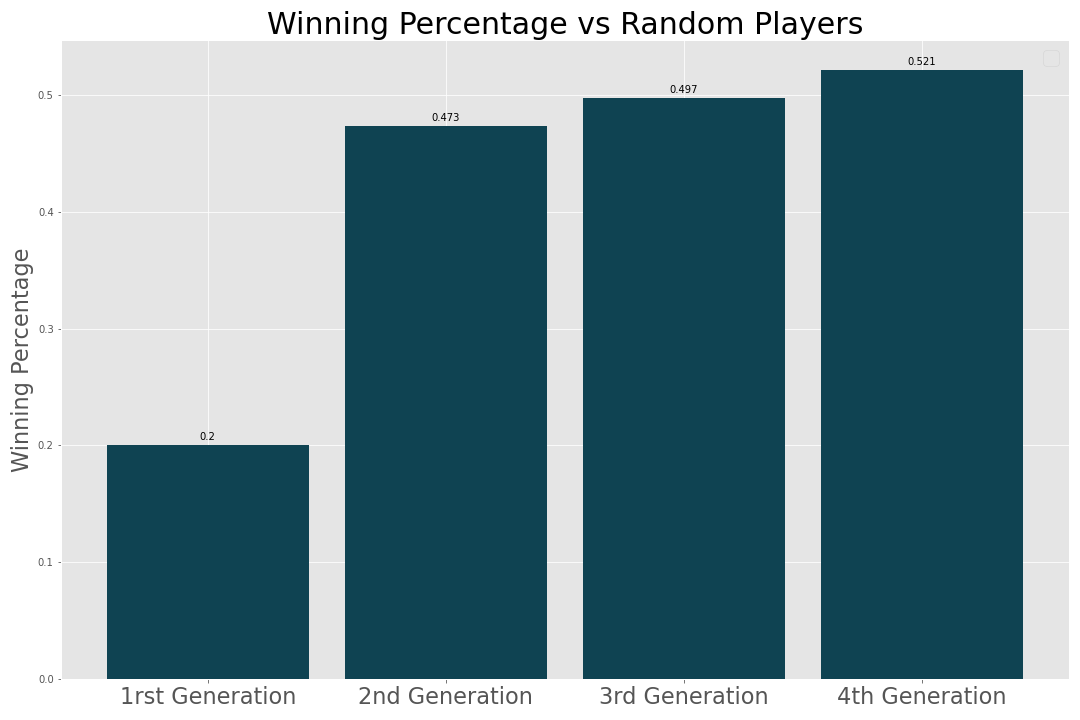
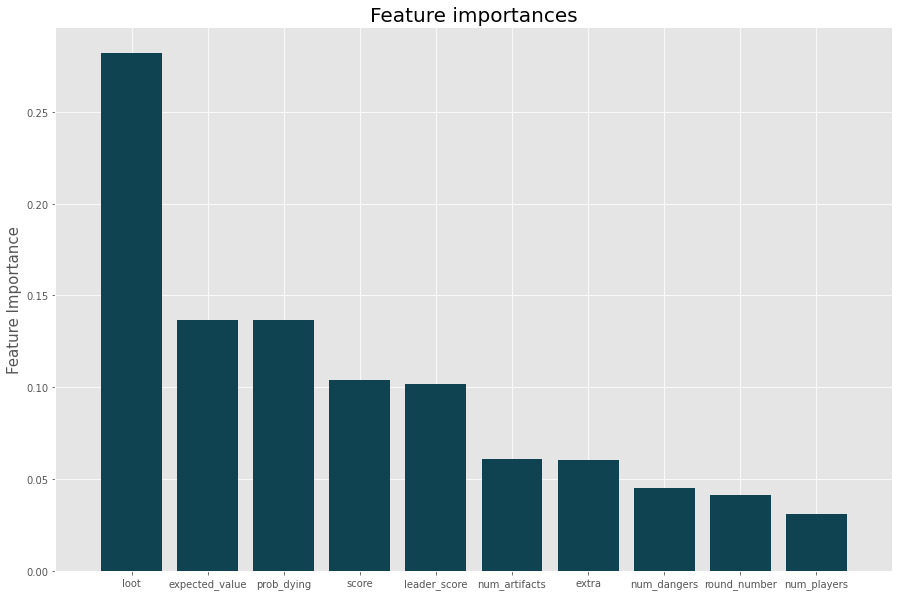
Each generation was trained using the winning results from 2000 simulated games pitting previous generations against each other. Each generation showed improvement in terms of winning percentage against the previous generation and winning percentage against players making random moves. Improvement leveled off after 4 generations of training with the best AI winning 52% of 5 player games against the random players. In addition, the 4th generation AI won 33 percent of 5 player games against the 3rd generation AI indicating a significant increase in performance. By using the feature importances metric for the final random forest model we can see how the AI is making decisions. The most important predictor was loot followed by the expected value of the next card and the probability of dying. It appears that the AIs primarily made their decision based on the amount of loot they had already accumulated which makes sense given that this predictor greatly influences the opportunity cost of the next move.
Conclusions:
The naive approach to training players yielded solid results. The AI players showed increased performance after each generation. This method was able to learn strategies despite having no knowledge of the rules of the game. The only reward signal for making the correct move was the moves made by the winning player. Other methods could potentially speed up training dramatically by assigning a score directly to the result of each move rather than waiting to the end of the game. The final AI was fairly challenging for a human player to beat especially since it had access to probability and expected value calculations that would be difficult for a human to compute live. However generally the human game involves more game theory and bluffing as human players interact with each other so it is difficult to compare performance.