
T5: Exploring the limits of Transfer Learning with a Unified Text to Text Transformer
Introduction
The T5 paper is a classic paper and is currently widely used as a standard model in research and industry. Notably, at the time of publication, it was the largest model in the world by parameter count. In addition, it introduced the idea of a transformer encoder-decoder architecture (concurrently with Facebook’s BART). Exhaustive experiments
-
What is the name of the T5 paper?
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Colin Rafel, Google
-
T5 is short for
Text to Text Transfer Transformer -
T5 frames every problem as a
Text to Text Task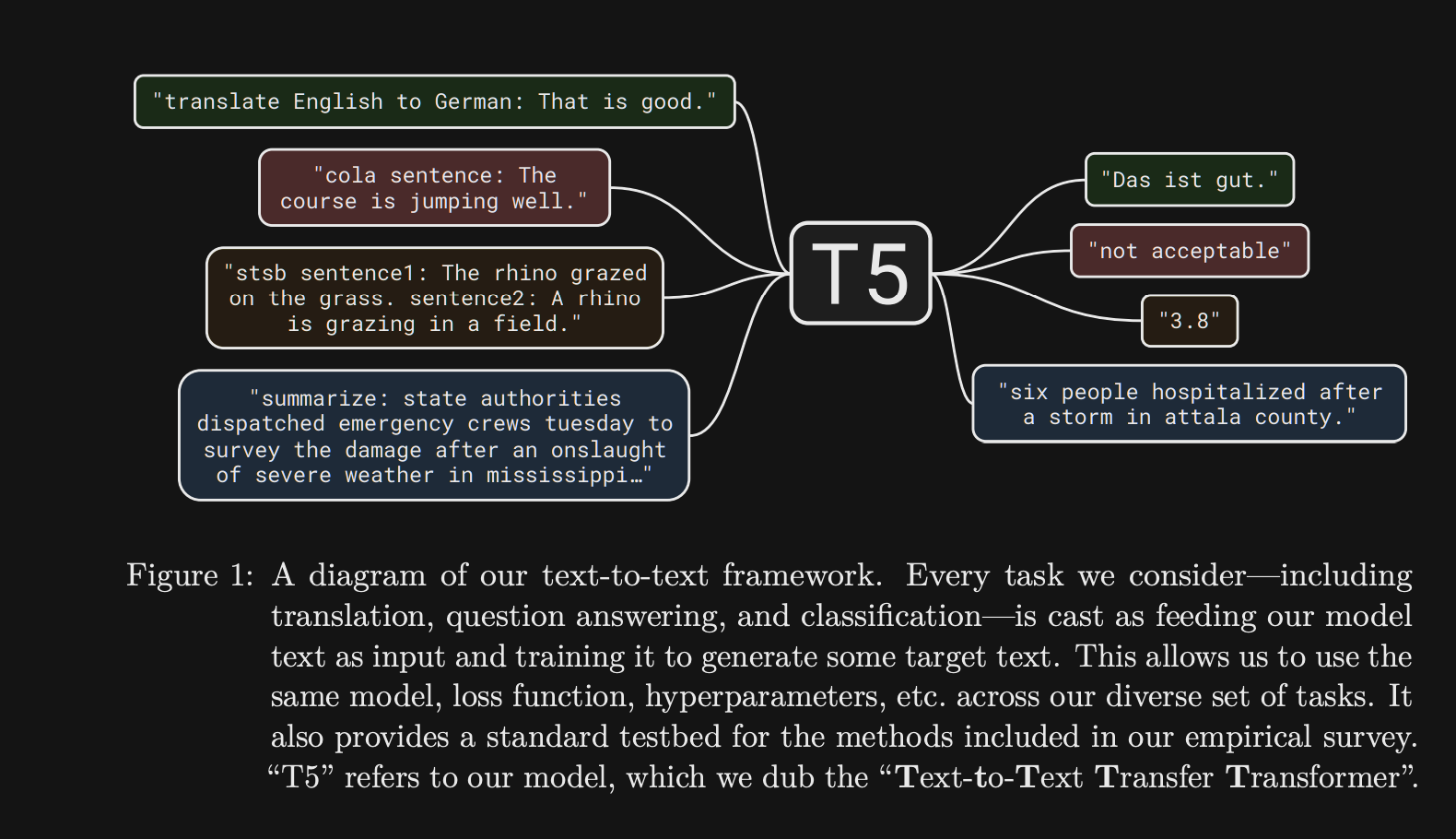
-
T5 introduces the
Colossal Clean Crawled CorpusC4 - 750 GB cleaned english text
- They train on the scraped webtext for one month in 2018
- What is the pretraining objective for T5?
- Masked spans of sentinel tokens (similar to BART)
- Maximum likelihood using teacher forcing
- Different from BART in that we predicting the full masked text rather than number of masked out tokens
-
In T5 the supervised pretraining object is
text to text with the target being the masked tokens
- T5 was trained for
1/4as many pretraining steps as BERT base- note: it is also a much larger model
-
T5 proposes the idea of a prefix attention mask to allow for better
representation of task specific prefixesIntuition: Prefix should be able to attend to itself, not just rely on previous tokens:
- Example: English prefix for NMT
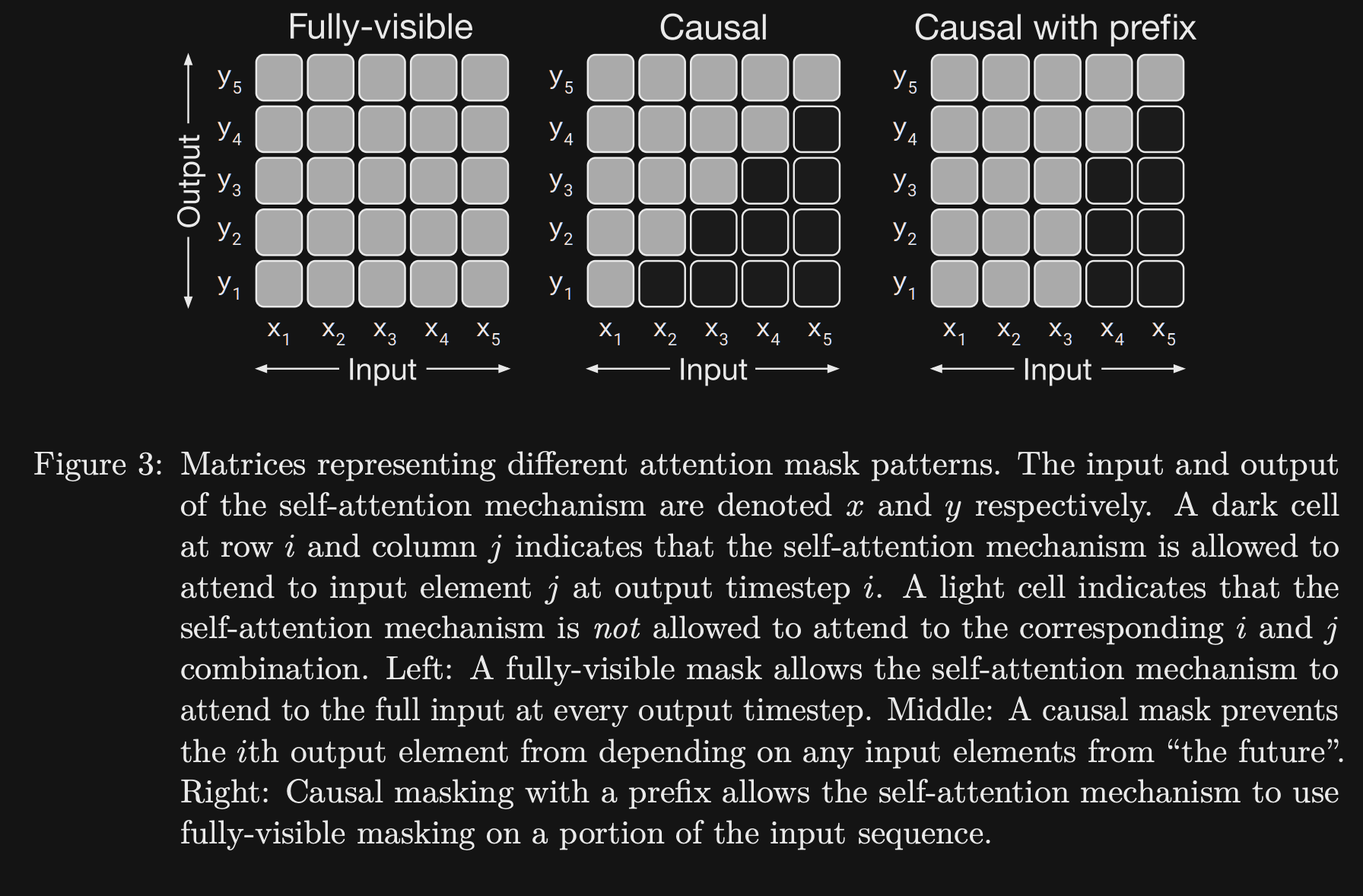
- Prefix Masking is useful in NMT to allow the
input sequence to attend to itself - Prefix Masking in T5 is analogous to BERT for classification in that
the input can attend to itself- BERT ends up with a representation in a classification token
- T5 outputs the correct classification from the language model itself
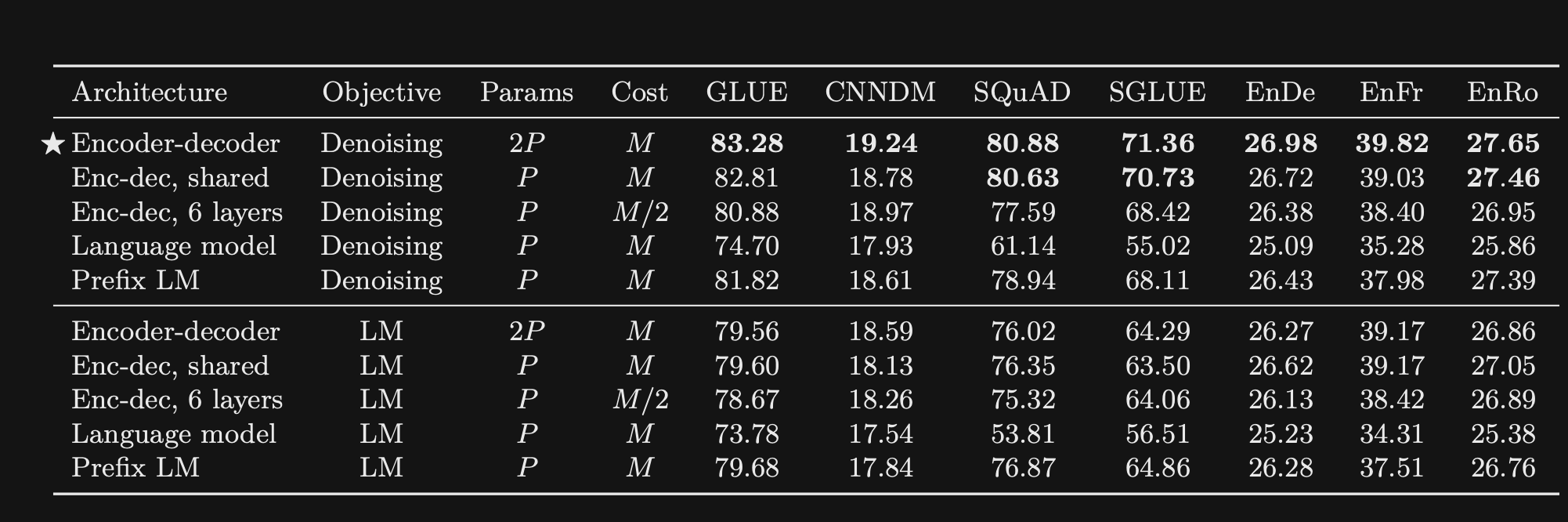
- How does the T5 paper compare encoder vs decoder vs encoder-decoder architectures?
- Assume the number of parameters/ flops is roughly the same
- They compared:

- The T5 paper experiments
validate the importanceof the denoising objective from BERT- Give better performance over simple LM
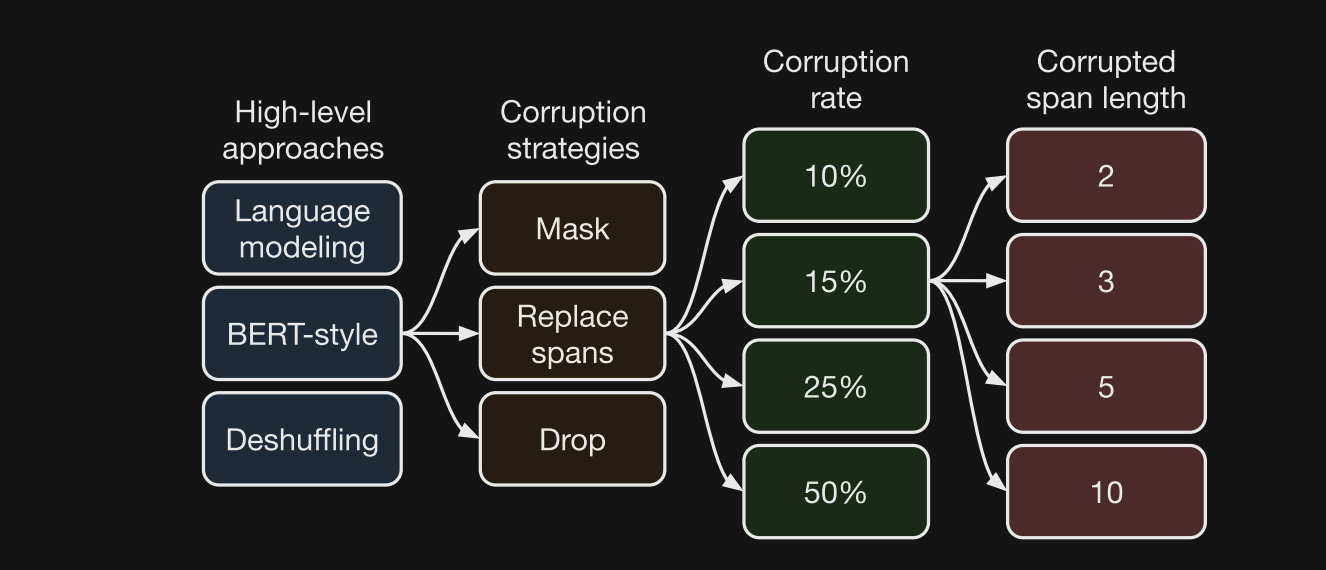
- The T5 paper compares various unsupervised objectives including BERT style
prefix language modelingdeshuffling- BERT style does the best
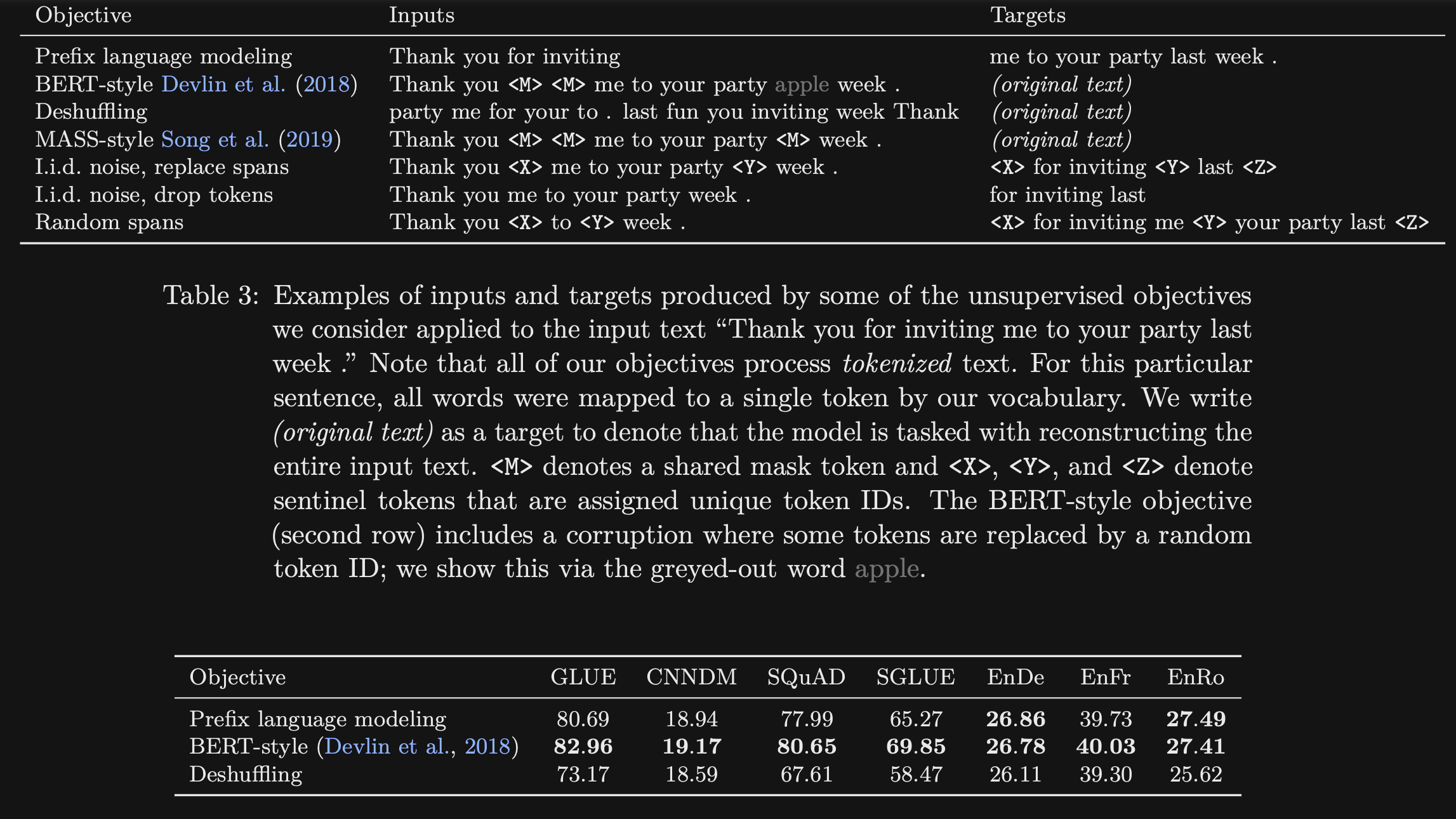
- What simplifications to BERT pretraining objectives does the TF paper explore?
- Only replacing with mask tokens (BERT replaces 15% with random tokens)
- Replace Corrupted Tokens
- Drop Corrupted Tokens
All showed similar performance

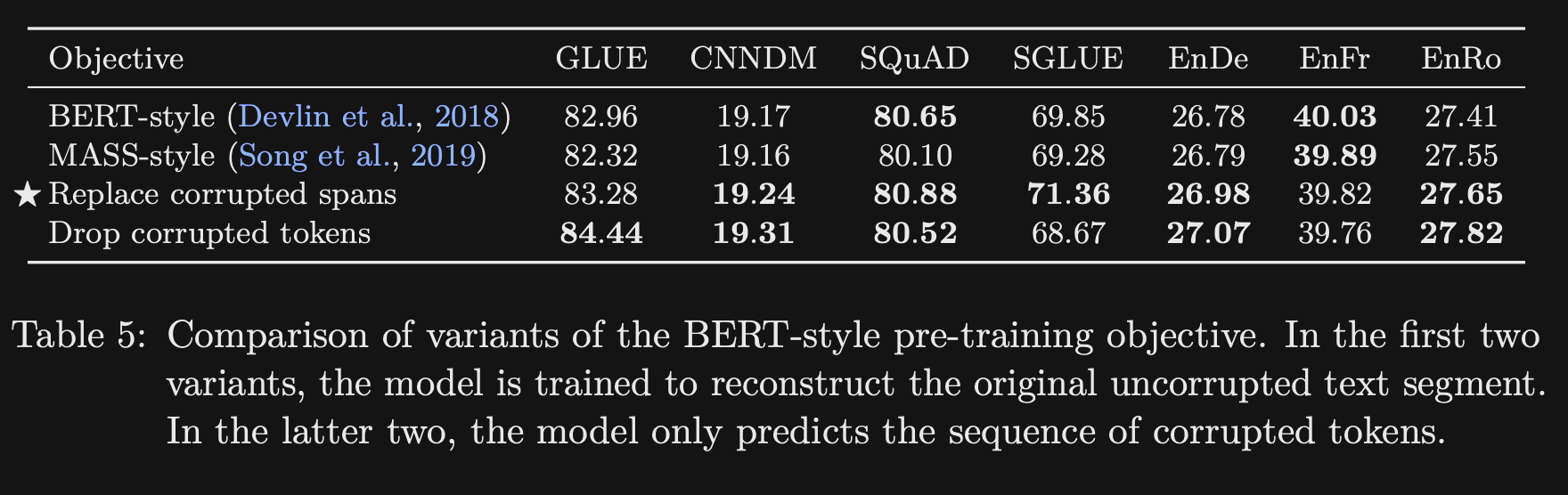
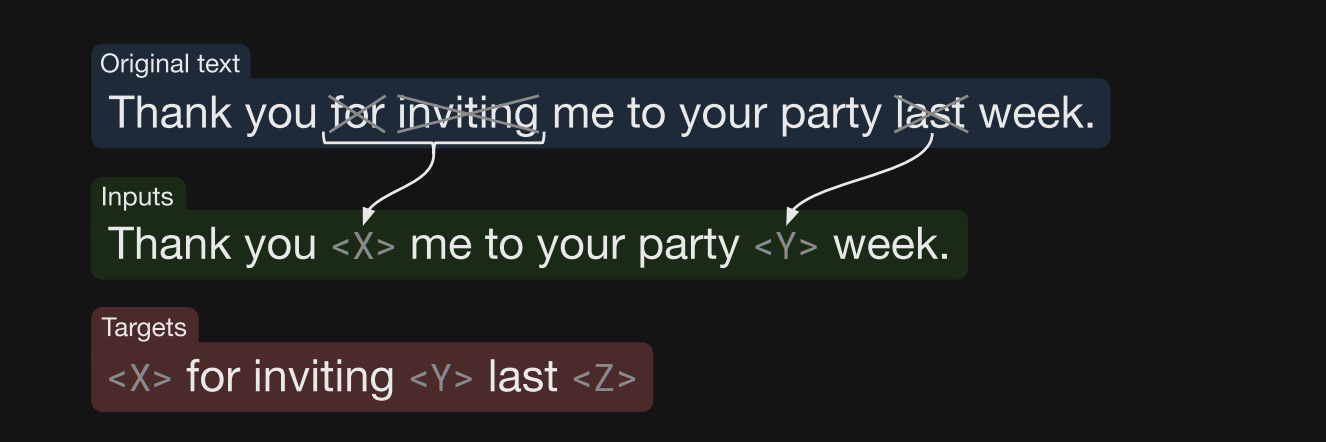
- The T5 variants of dropping corrupted tokens or replacing corrupted spans is appealing because it
reduces training timecompared to the regular BERT objective- the target sequence has to attend over a smaller number of tokens
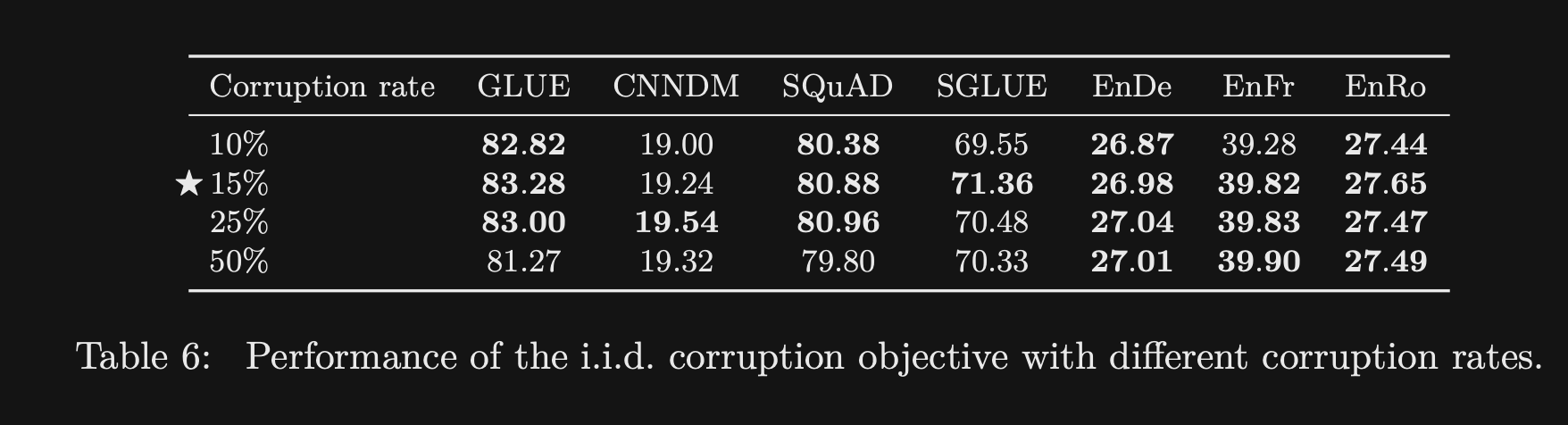
- The T5 paper compared the effect of different corruption rates during pretraining and showed
no significant difference- Stick with 15% from BERT
- note: would expect performance to eventually degrade at higher rates
- T5 showed that corrupting spans rather than individual tokens had
small effect- Larger spans do have lower computational cost, due to representation as one token
- Similar result was found in the spanBERT paper
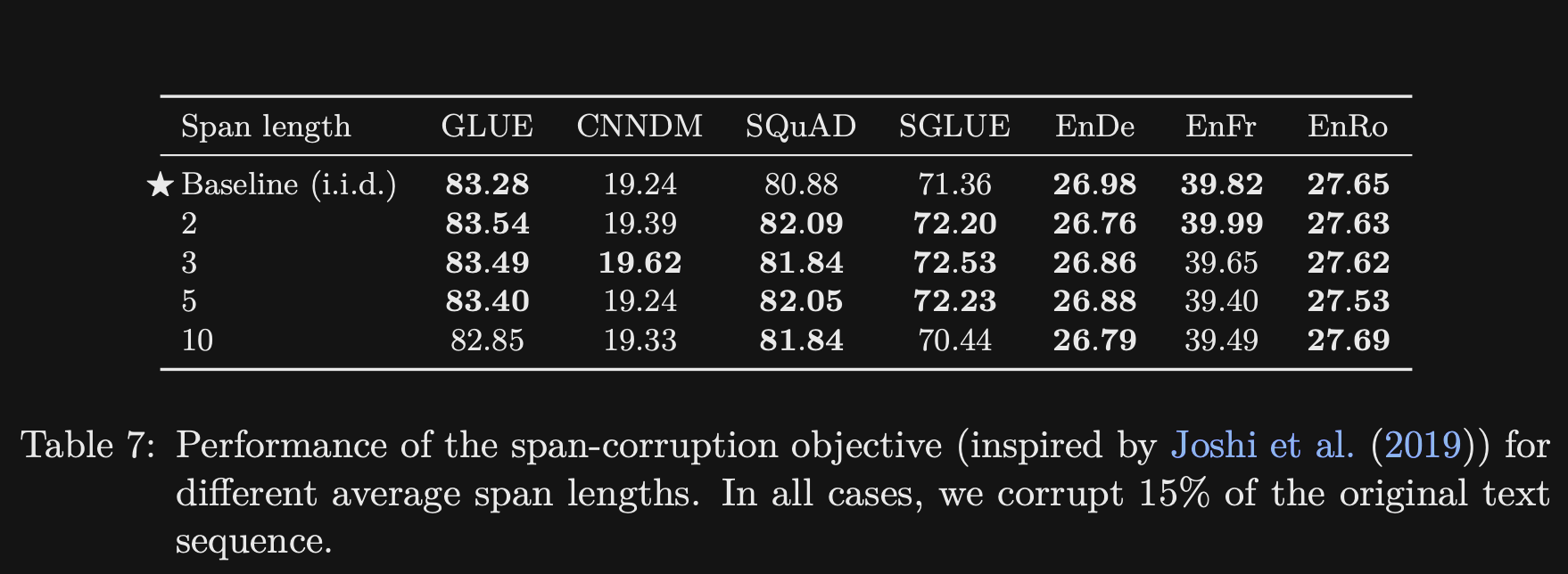
- Overall the T5 study on pretraining objectives showed
small differences among MLM variants- Should also consider which variants have the lowest pretraining time
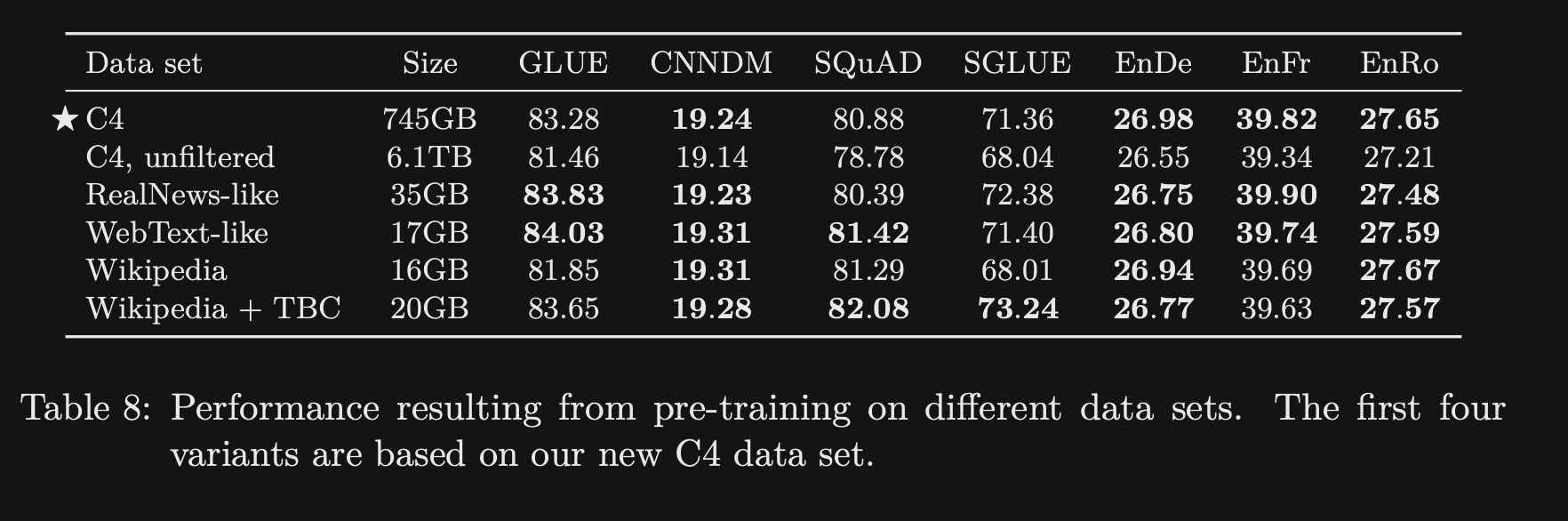
- T5 compared different pretraining datasets and showed that domain specific datasets impacted
performance on specific downstream tasks- Should pretrain on a relevant dataset for your task
- T5 experiments showed performance
decreasedwith less training data- Comparison is with equal numbers of pretraining steps
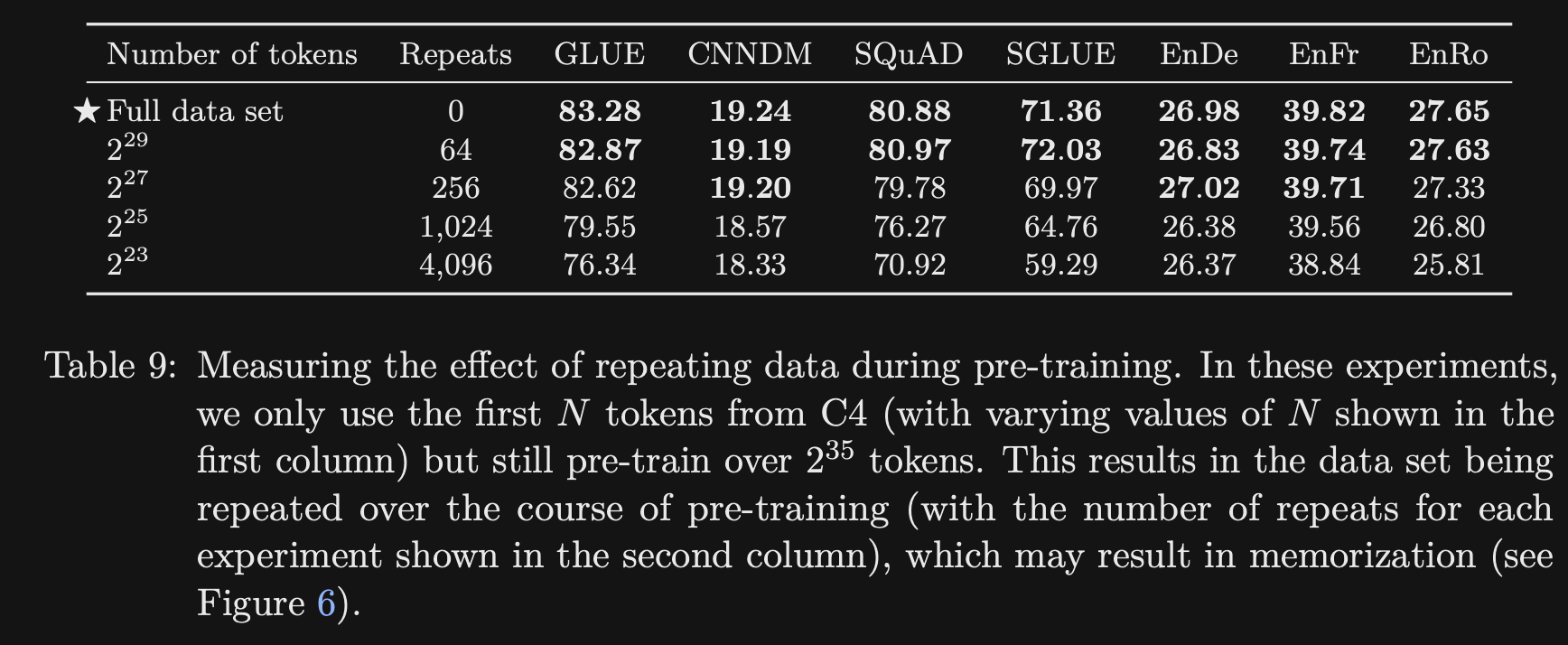
- Training on the full dataset once outperformed training on 1/64th of the dataset 64 times
- note: this provides decent empirical support for the current paradigm of training large language models for a single epoch
-
What transformer finetuning approaches are compared in T5?
Note: Normal finetuning of a classifier on top of [cls] token representations as in BERT is not relevant for these encoder decoder models.
- Adapter Layers: Add additional dense layers within each transformer block
- Vary d, the inner dimension of these adapter layers
- also have to update layernorm parameters
- Gradual Unfreezing: Gradually finetune more and more layers
- Adapter Layers: Add additional dense layers within each transformer block
- T5 finetuning experiments showed
degradation in performance- was best to train all parameters
- this is similar to the finding in the GOPHER finetuning experiments
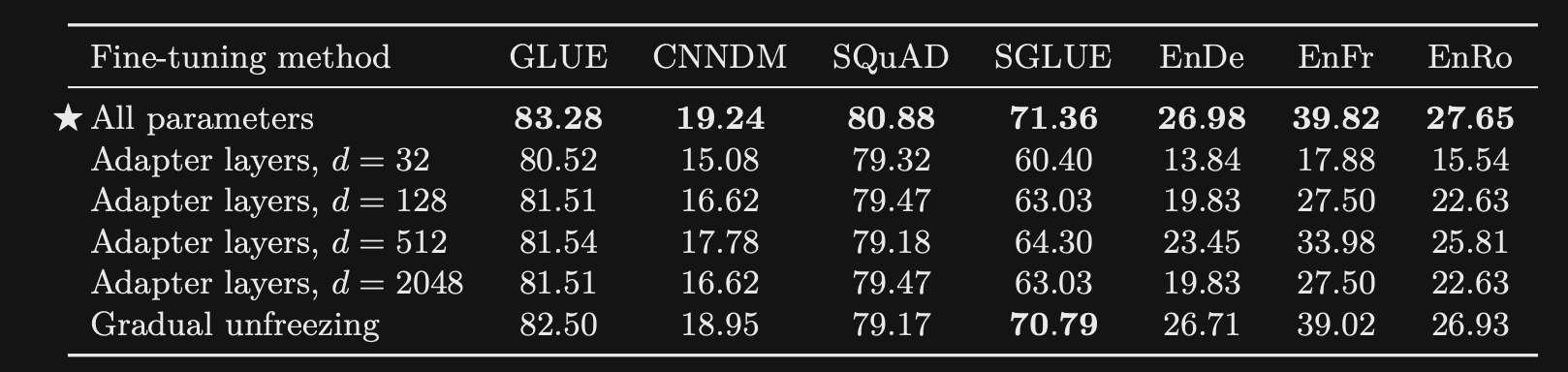
-
What approaches to multitask learning are explored in T5?
Multitask learning with their architecture is equivalent to doing the unsupervised training step of mixtures of different datasets
- Examples Proportional Mixing
- Temperature Scaled Mixing:
- increasing temperature decreases imbalance between dataset sizes
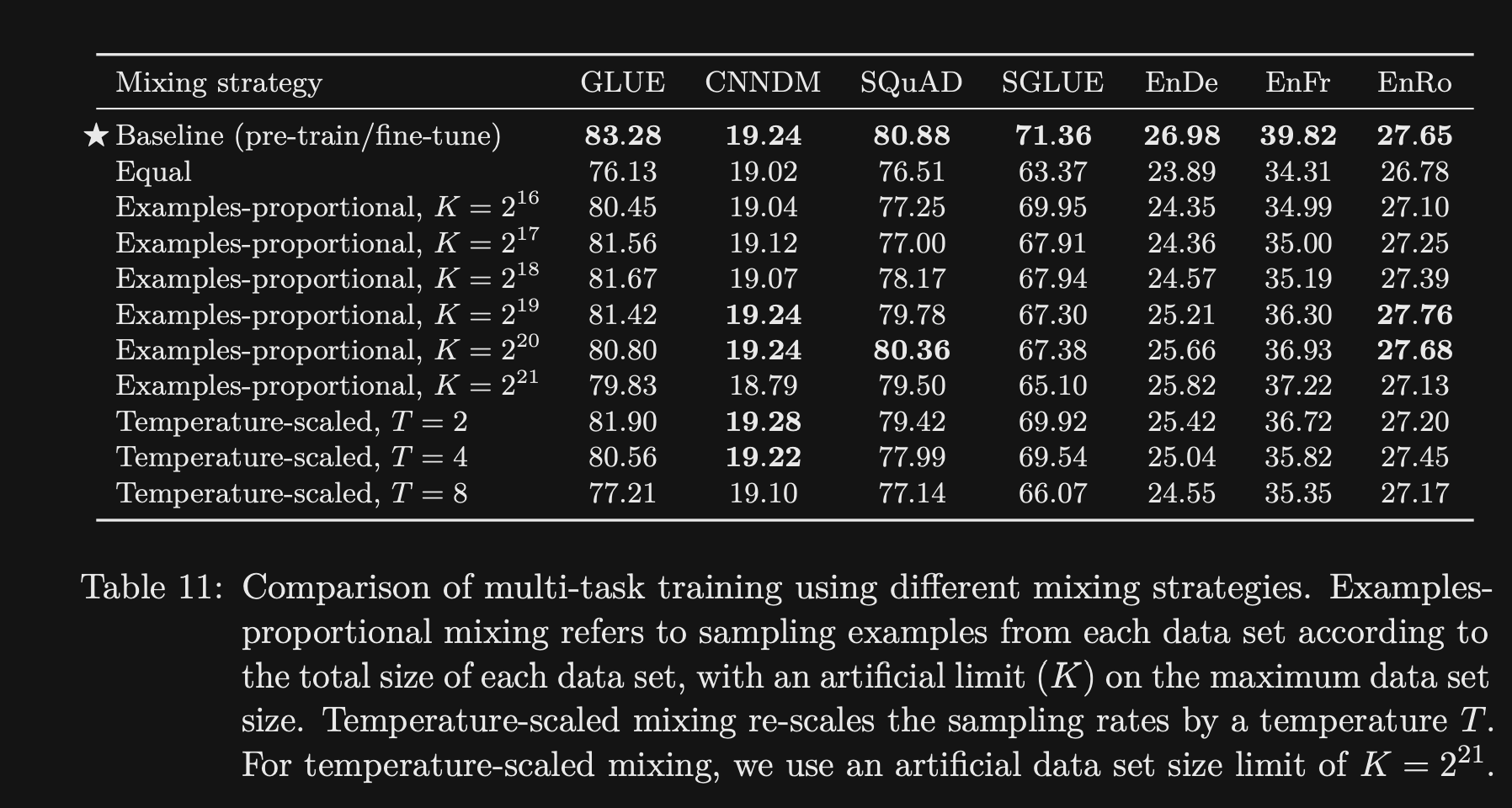
- How does the T5 paper reveal the “bitter lesson” in machine learning?
- The bitter lesson is that scale/ computation is all that matters
- T5 showed marginal difference between lots of different training objectives and datasets
- Large scale of the model (11B parameters) seems to be all that is necessary to perform well
- Ex: GPT3
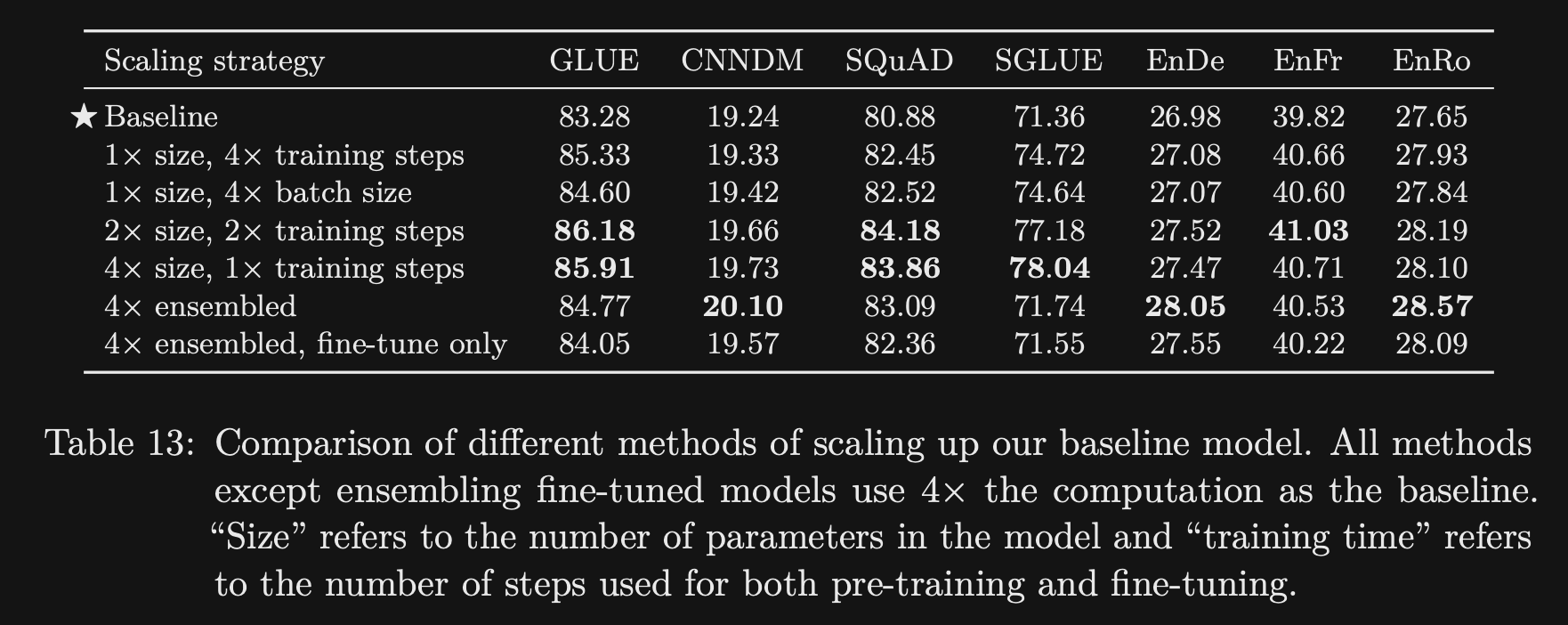
- What scaling techniques does the T5 paper explore?
- Increasing size
- Increasing training steps
- increasing batch size
- Ensembling (average logits of multiple models)
Increasing size seemed to do the best
-
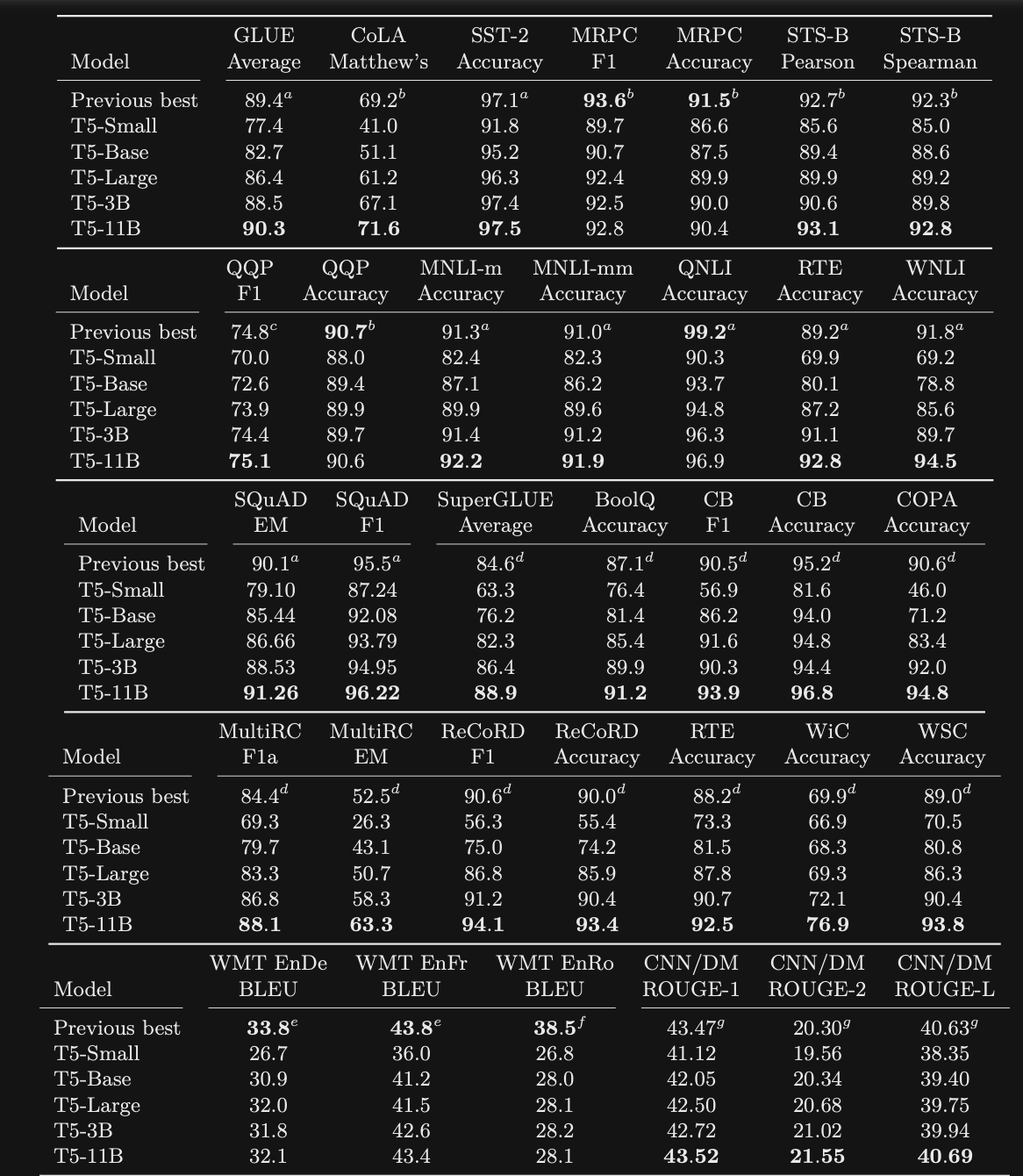
T5 results: achieved SOTA on
most GLUE and super GLUE tasksNote 11B model is 30 times larger than BERT
Conclusion
T5 is an important paper that introduced a new encoder-decoder transformer model. The exhaustive experiments provide insight into pre-training objectives, finetuning approaches and dataset selection. The T5 model forms the basis for many other works notably PromptTuning, ExT5, and T0. Many checkpoints are available from Huggingface.
Reference
@article{DBLP:journals/corr/abs-1910-10683,
author = {Colin Raffel and
Noam Shazeer and
Adam Roberts and
Katherine Lee and
Sharan Narang and
Michael Matena and
Yanqi Zhou and
Wei Li and
Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text
Transformer},
journal = {CoRR},
volume = {abs/1910.10683},
year = {2019},
url = {http://arxiv.org/abs/1910.10683},
eprinttype = {arXiv},
eprint = {1910.10683},
timestamp = {Fri, 05 Feb 2021 15:43:41 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1910-10683.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}