
TransformerXL
Introduction
Transformer models typically have a fixed context window that is hard to scale due to the $O(n^2)$ cost of the attention mechanism. Extending the context window can have many benefits when modeling longer pieces of text such as paragraphs or books. The TransformerXL paper extends the vannilla transformer architecture with a simple recurrence mechanism to allow for longer range contexts. They present improved results primarily on the Language Modeling Perplexity of various datasets.
-
What is the name of the Transformer XL paper?
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Zihang Dai, CMU/ Google Brain
- The major achievement of transformerXL is the
ability to capture more long range dependencies- Longer context than RNNs or vanilla transformers
- The paper introduces a elative rather than absolute positional embedding
- A problem with Vanilla transformers is the fixed
context size- doesn’t necessarily respect sentence boundaries
- Have to compute over again at each step
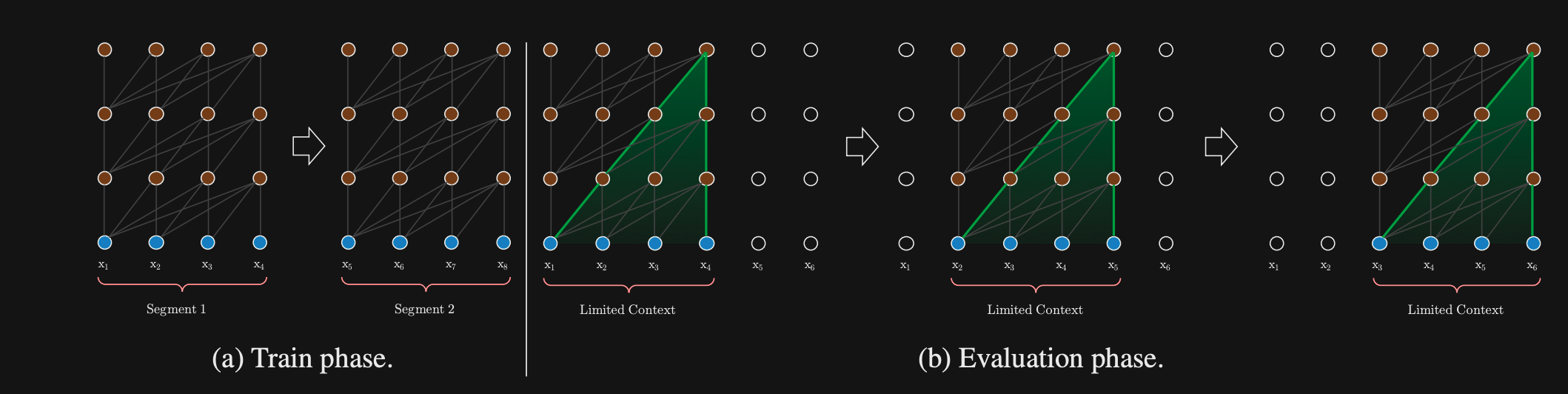
- TransformerXL seeks to extend the context window of transformers by introducing a
recurrence mechanism- Cache hidden state representation of previous context window
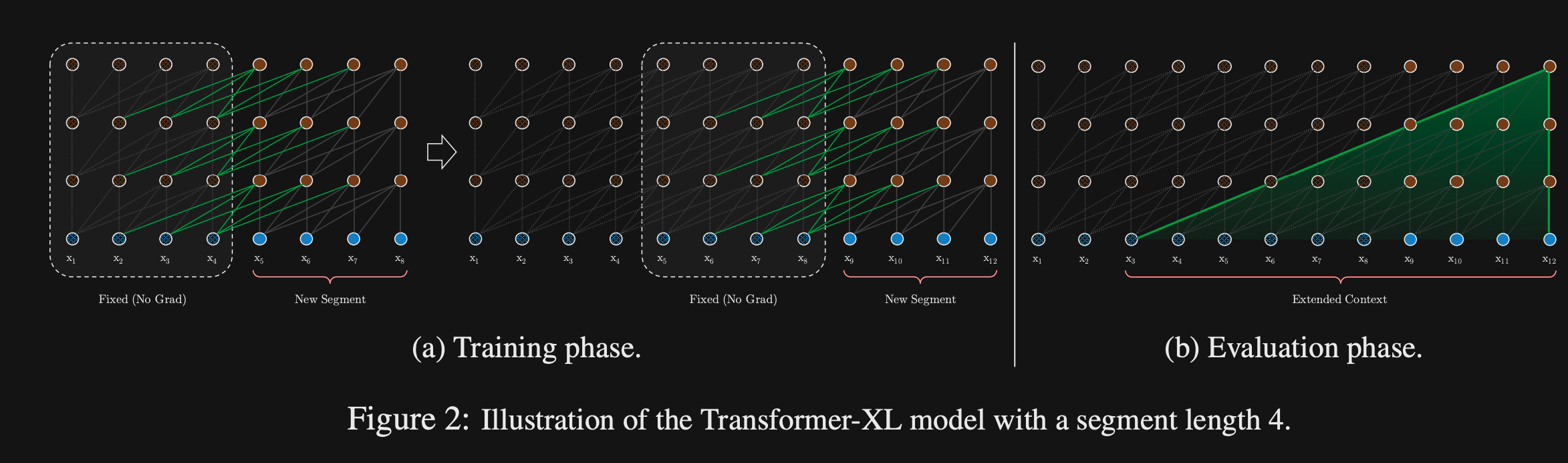
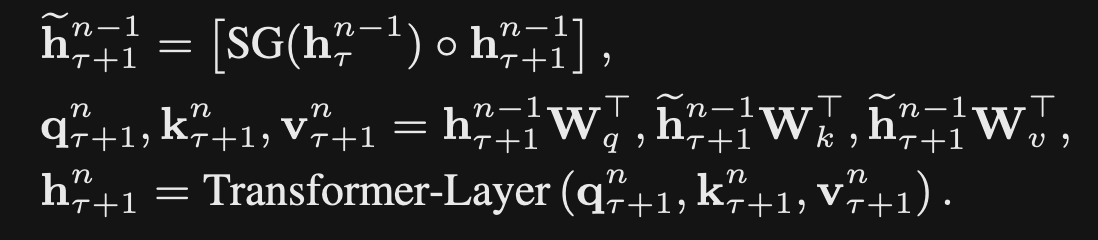
- TransformerXL
concatenatesthe previous context windows hidden state- Do not update the gradients for the previous representation
- The query will attend over both the current context window and the cached hidden state activations for the previous context window
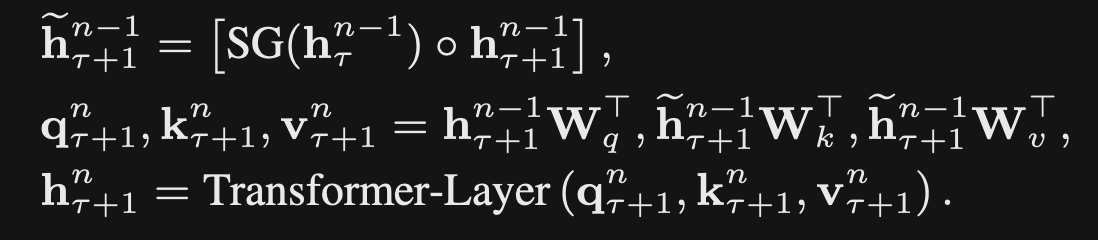
- The amount of context encoded by transformersXL is dependent on the
number of transformer layers- Context from lower transformer layers will propagate further
- Maximum size of context will be $O(N xL)$ where $N$ is the number of transformer layers and $L$ is the size of the regular context window
- Note: there still may be a dropoff in the quality of the context representation at longer ranges because it has comes from only the lower layers of the transformer.
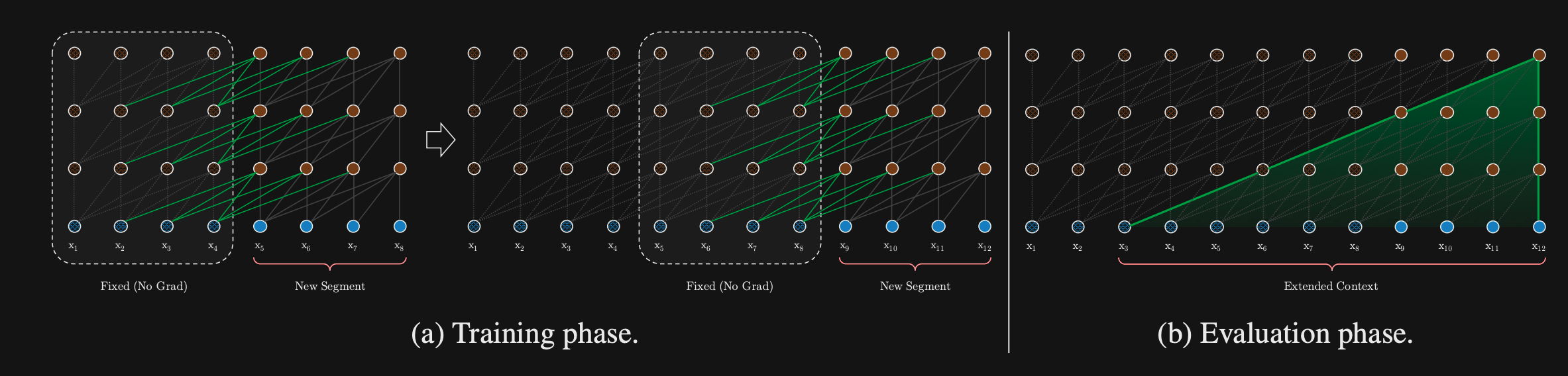
- TransformerXL incorporates more previous context using
relative positional embeddings- Sinusoidal with no learned Parameters
- What is the key idea behind relative positional embeddings?
- A query doesn’t need to know the absolute position of a key, only the position relative to itself
-
How can the attention score in transformers be factored out to see the impact of embeddings and content vectors?
FOIL
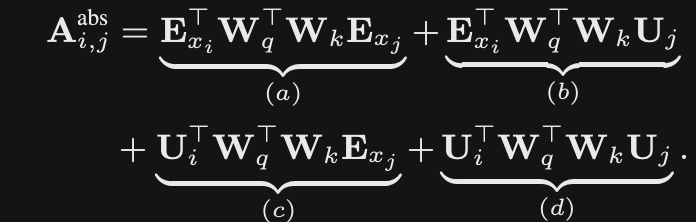
-
The relative positional embedding in transformersXL replaces absolute positional embeddings for the
key vectorsR is the sinusoidal relative positional embedding
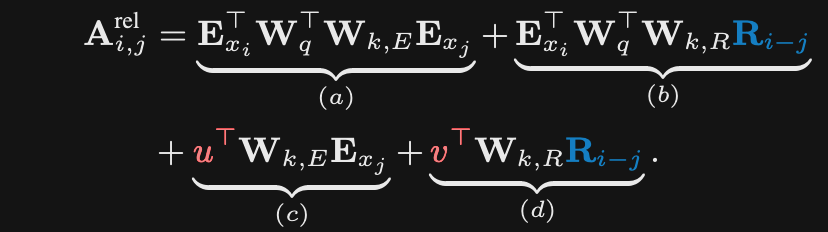
- Also replaces the positional embedding for the query with a learned constant
- Intuition is that no information is lost since we have a relative embedding between query and key
- Finally separates out positional and content parts of the key generation
- Also replaces the positional embedding for the query with a learned constant
-
TransformerXL relative positional embeddings replace the positional embeddings for query vectors because
information is already encoded in relative key vector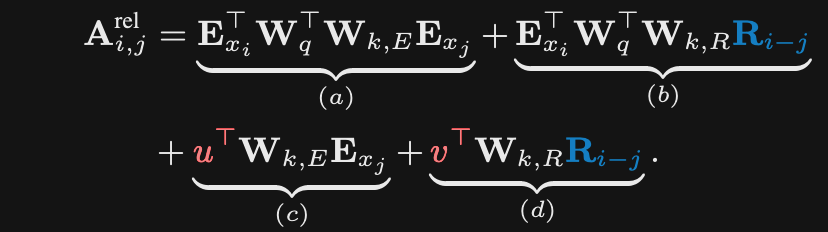
-
TransformerXL achieves SOTA
perplexityresults on many datasets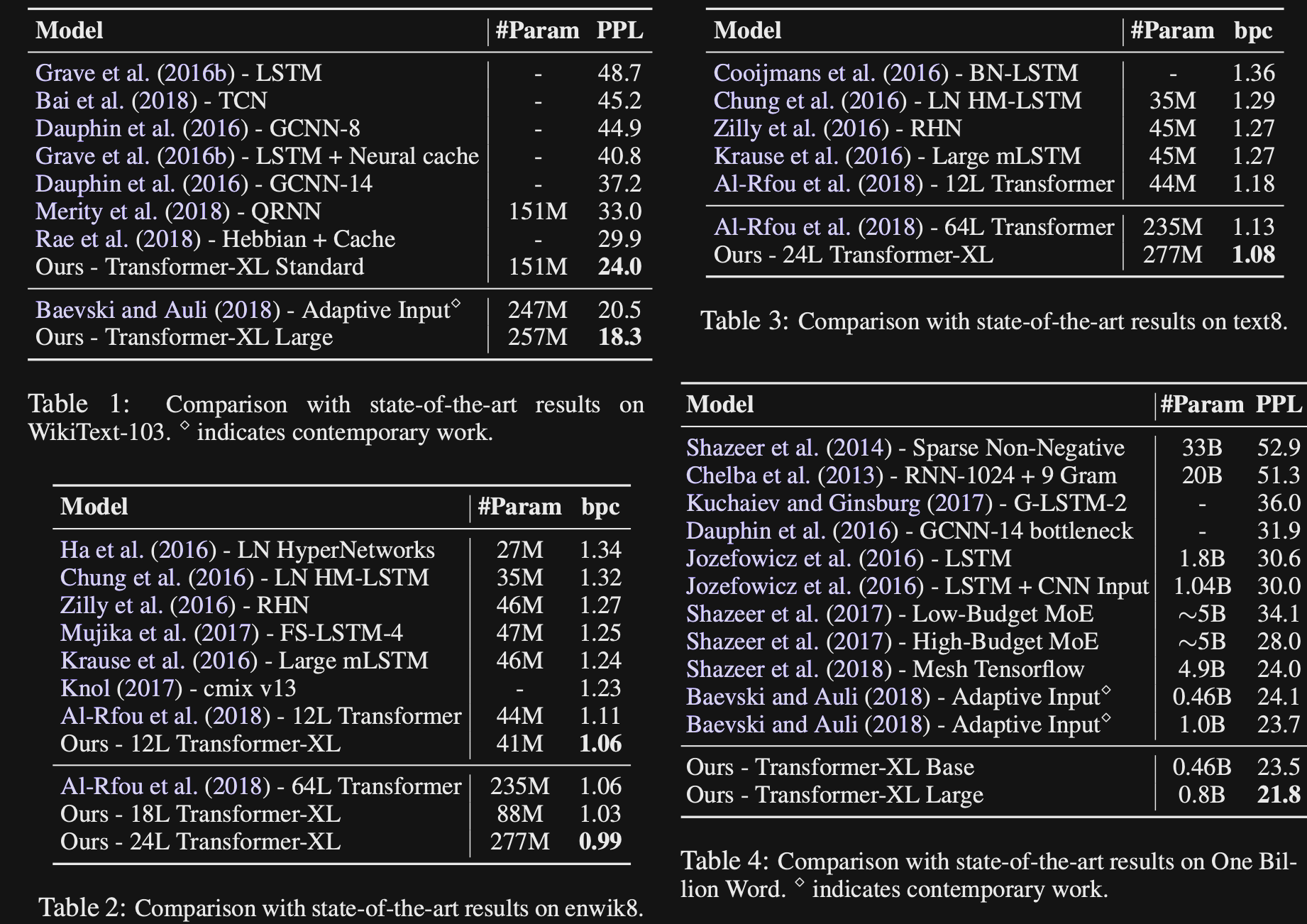
Conclusion
This is a nice paper that explores a simple recurrent method to extend the context window of transformer based langauge models. TransformerXL was used as a backbone for other very interesting models such as XLNET and ERNIE. Note that the bold claim of being up to 1800 times faster at inference time is a bit of a false comparison. This comparison is to a naive vanilla transformer approach that does not take advantage of any caching. In reality the performance is likely to by relatively similar.The paper also presents random samples of generated text from TransformerXL. The text looks relatively coherent. However, it is difficult to tell if the architecture maintains long range coherency of generated text better than other models.
Reference
@article{dai2019transformerxl,
title={Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context },
author={Zihang Dai and Zhilin Yang and Yiming Yang and Jaime Carbonell and Quoc V. Le and Ruslan Salakhutdinov },
year={2019},
journal={arXiv preprint arXiv: Arxiv-1901.02860}
}